The Ubuntu Studio team is pleased to announce the release of Ubuntu Studio 24.04 LTS, code-named “Noble Numbat”. This marks Ubuntu Studio’s 34th release. This release is a Long-Term Support release and as such, it is supported for 3 years (36 months, until April 2027).
Since it’s just out, you may experience some issues, so you might want to wait a bit before upgrading. Please see the release notes for a more complete list of changes and known issues. Listed here are some of the major highlights.
You can download Ubuntu Studio 24.04 LTS from our download page.
Special Notes
The Ubuntu Studio 24.04 LTS disk image (ISO) exceeds 4 GB and cannot be downloaded to some file systems such as FAT32 and may not be readable when burned to a standard DVD. For this reason, we recommend downloading to a compatible file system. When creating a boot medium, we recommend creating a bootable USB stick with the ISO image or burning to a Dual-Layer DVD.
Minimum installation media requirements: Dual-Layer DVD or 8GB USB drive.
Images can be obtained from this link: https://cdimage.ubuntu.com/ubuntustudio/releases/24.04/beta/
Full updated information, including Upgrade Instructions, are available in the Release Notes.
Please note that upgrading from 22.04 before the release of 24.04.1, due August 2024, is unsupported.
Upgrades from 23.10 should be enabled within a month after release, so we appreciate your patience.
New This Release
All-New System Installer
In cooperation with the Ubuntu Desktop Team, we have an all-new Desktop installer. This installer uses the underlying code of the Ubuntu Server installer (“Subiquity”) which has been in-use for years, with a frontend coded in “Flutter”. This took a large amount of work for this release, and we were able to help a lot of other official Ubuntu flavors transition to this new installer.
Be on the lookout for a special easter egg when the graphical environment for the installer first starts. For those of you who have been long-time users of Ubuntu Studio since our early days (even before Xfce!), you will notice exactly what it is.
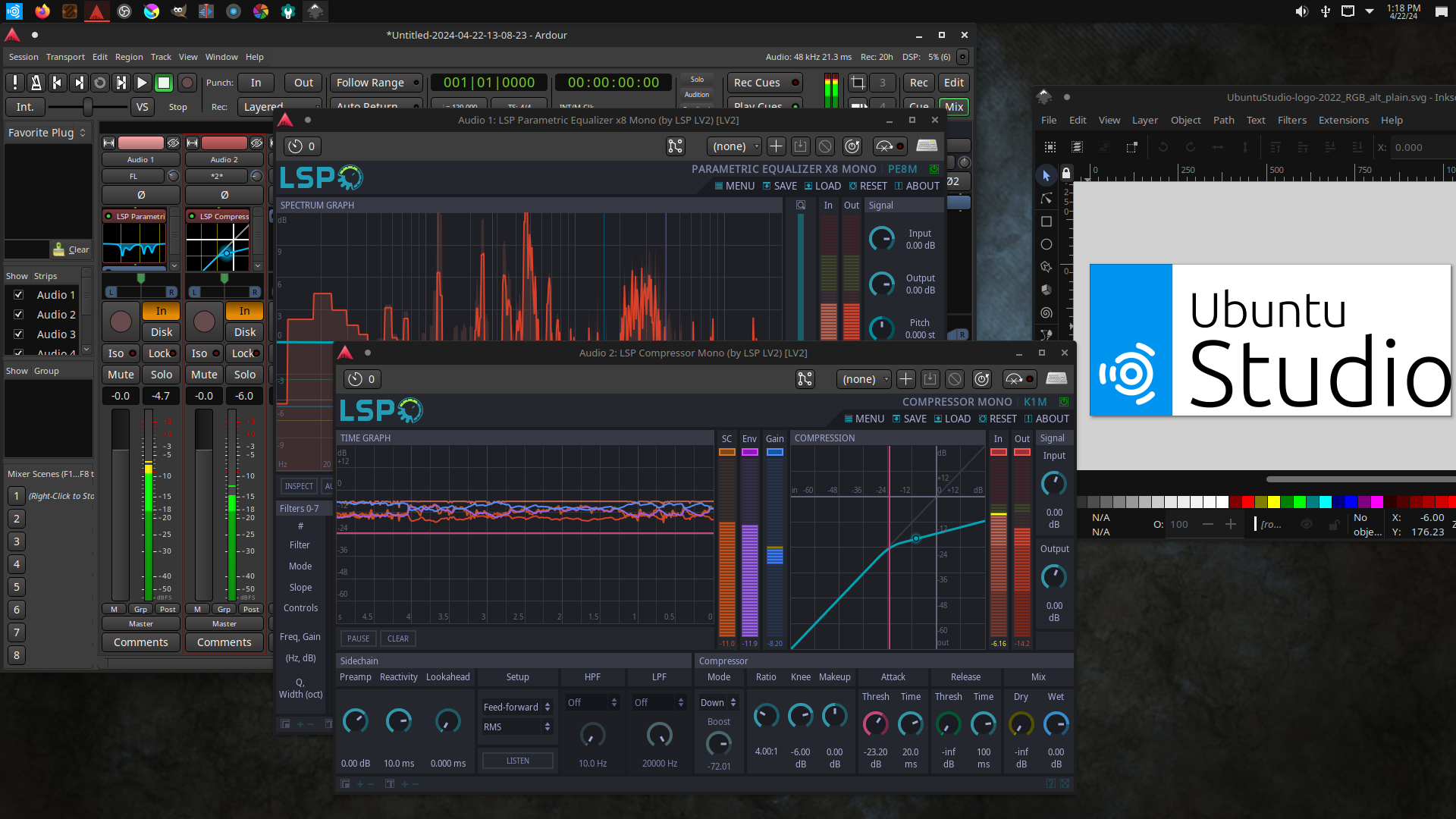
PipeWire 1.0.4
Now for the big one: PipeWire is now mature, and this release contains PipeWire 1.0. With PipeWire 1.0 comes the stability and compatibility you would expect from multimedia audio. In fact, at this point, we recommend PipeWire usage for both Professional, Prosumer, and Everyday audio needs. At Ubuntu Summit 2023 in Riga, Latvia, our project leader Erich Eickmeyer used PipeWire to demonstrate live audio mixing with much success and has since done some audio mastering work using it. JACK developers even consider it to be “JACK 3”.
PipeWire’s JACK compatibility is configured to use out-of-the-box and is zero-latency internally. System latency is configurable via Ubuntu Studio Audio Configuration.
However, if you would rather use straight JACK 2 instead, that’s also possible. Ubuntu Studio Audio Configuration can disable and enable PipeWire’s JACK compatibility on-the-fly. From there, you can simply use JACK via QJackCtl.
With this, we consider audio production with Ubuntu Studio so mature that it can now rival operating systems such as macOS and Windows in ease-of-use since it’s ready to go out-of-the-box.
Deprecation of PulseAudio/JACK setup/Studio Controls
Due to the maturity of PipeWire, we now consider the traditional PulseAudio/JACK setup, where JACK would be started/stopped by Studio Controls and bridged to PulseAudio, deprecated. This configuration is still installable via Ubuntu Studio Audio Configuration, but we do not recommend it. Studio Controls may return someday as a PipeWire fine-tuning solution, but for now it is unsupported by the developer. For that reason, we recommend users not use this configuration. If you do, it is at your own risk and no support will be given. In fact, it’s likely to be dropped for 24.10.
Ardour 8.4
While this does not represent the latest release of Ardour, Ardour 8.4 is a great release. If you would like the latest release, we highly recommend purchasing one-time or subscribing to Ardour directly from the developers to help support this wonderful application. Also, for that reason, this will be an application we will not directly backport. More on that later.
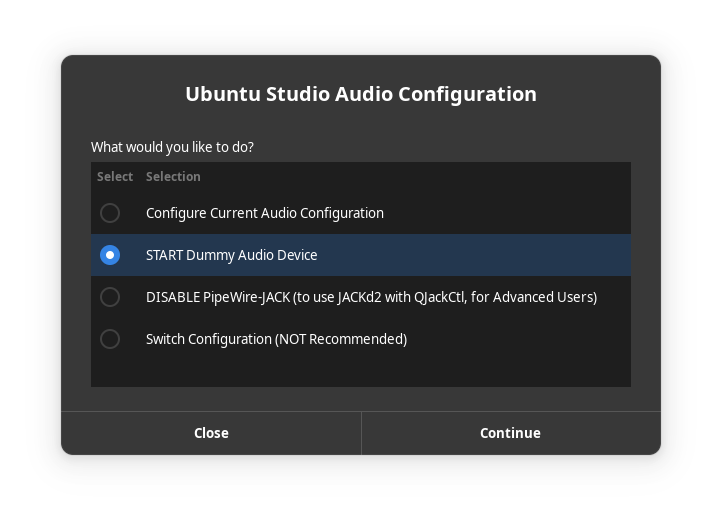
Ubuntu Studio Audio Configuration
Ubuntu Studio Audio Configuration has undergone a UI overhaul and contains the ability to start and stop a Dummy Audio Device which can also be configured to start or stop upon login. When assigned as the default, this will free-up channels that would normally be assigned to your system audio to be assigned to a null device.
Meta Package for Music Education
In cooperation with Edubuntu, we have created a metapackage for music education. This package is installable from Ubuntu Studio Installer and includes the following packages:
- FMIT: Free Musical Instrument Tuner, a tool for tuning musical Instruments (also included by default)
- GNOME Metronome: Exactly what it sounds like (pun unintended): a metronome.
- Minuet: Ear training for intervals, chords, scales, and more.
- MuseScore: Create, playback, and print sheet music for free (this one is no stranger to the Ubuntu Studio community)
- Piano Booster: MIDI player/game that displays musical notes and teaches you how to play piano, optionally using a MIDI keyboard.
- Solfege: Ear training program for harmonic and melodic intervals, chords, scales, and rhythms.
New Artwork
Thanks to the work of Eylul and the submissions to the Ubuntu Studio Noble Numbat Wallpaper Contest, we have a number of wallpapers to choose from and a new default wallpaper.
Deprecation of Ubuntu Studio Backports Is In Effect
As stated in the Ubuntu 23.10 Release Announcement, the Ubuntu Studio Backports PPA is now deprecated in favor of the official Ubuntu Backports repository. However, the Backports repository only works for LTS releases and for good reason. There are a few requirements for backporting:
- It must be an application which already exists in the Ubuntu repositories
- It must be an application which would not otherwise qualify for a simple bugfix, which would then qualify it to be a Stable Release Update. This means it must have new features.
- It must not rely on new libraries or new versions of libraries.
- It must exist within a later supported release or the development release of Ubuntu.
If you have a suggestion for an application for which to backport that meets those requirements, feel free to join and email the Ubuntu Studio Users Mailing List with your suggestion with the tag “[BPO]” at the beginning of the subject line. Backports to 22.04 LTS are now closed and backports to 24.04 LTS are now open. Additionally, suggestions must pertain to Ubuntu Studio and preferably must be applications included with Ubuntu Studio. Suggestions can be rejected at the Project Leader’s discretion.
One package that is exempt to backporting is Ardour. To help support Ardour’s funding, you may obtain later versions directly from them. To do so, please one-time purchase or subscribe to Ardour from their website. If you wish to get later versions of Ardour from us, you will have to wait until the next regular release of Ubuntu Studio, due in October 2024.
We’re back on Matrix
You’ll notice that the menu links to our support chat and on our website will now take you to a Matrix chat. This is due to the Ubuntu community carving its own space within the Matrix federation.
However, this is not only a support chat. This is also a creativity discussion chat. You can pass ideas to each other and you’re welcome to it if the topic remains within those confines. However, if a moderator or admin warns you that you’re getting off-topic (or the intention for the chat room), please heed the warning.
This is a persistent connection, meaning if you close the window (or chat), it won’t lose your place as you may only need to sign back in to resume the chat.
Frequently Asked Questions
Q: Does Ubuntu Studio contain snaps?
A: Yes. Mozilla’s distribution agreement with Canonical changed, and Ubuntu was forced to no longer distribute Firefox in a native .deb package. We have found that, after numerous improvements, Firefox now performs just as well as the native .deb package did.
Thunderbird also became a snap during this cycle for the maintainers to get security patches delivered faster.
Additionally, Freeshow is an Electron-based application. Electron-based applications cannot be packaged in the Ubuntu repositories in that they cannot be packaged in a traditional Debian source package. While such apps do have a build system to create a .deb binary package, it circumvents the source package build system in Launchpad, which is required when packaging for Ubuntu. However, Electron apps also have a facility for creating snaps, which can be uploaded and included. Therefore, for Freeshow to be included in Ubuntu Studio, it had to be packaged as a snap.
Q: Will you make an ISO with {my favorite desktop environment}?
A: To do so would require creating an entirely new flavor of Ubuntu, which would require going through the Official Ubuntu Flavor application process. Since we’re completely volunteer-run, we don’t have the time or resources to do this. Instead, we recommend you download the official flavor for the desktop environment of your choice and use Ubuntu Studio Installer to get Ubuntu Studio – which does *not* convert that flavor to Ubuntu Studio but adds its benefits.
Q: What if I don’t want all these packages installed on my machine?
A: Simply use the Ubuntu Studio Installer to remove the features of Ubuntu Studio you don’t want or need!
Looking Toward the Future
Plasma 6
Ubuntu Studio, in cooperation with Kubuntu, will be switching to Plasma 6 during the 24.10 development cycle. Likewise, Lubuntu will be switching to LXQt 2.0 and Qt 6, so the three flavors will be cooperating to do the move.
New Look
Ubuntu Studio has been using the same theming, “Materia” (except for the 22.04 LTS release which was a re-colored Breeze theme) since 19.04. However, Materia has gone dead upstream. To stay consistent, we found a fork called “Orchis” which seems to match closely and will be switching to that. More on that soon.
Minimal Installation
The new system installer has the capability to do minimal installations. This was something we did not have time to implement this cycle but intend to do for 24.10. This will let users install a minimal desktop to get going and then install what they need via Ubuntu Studio Installer. This will make a faster installation process but will not make the installation .iso image smaller. However, we have an idea for that as well.
Minimal Installation .iso Image
We are going to research what it will take to create a minimal installer .iso image that will function much like the regular .iso image minus the ability to install everything and allow the user to customize the installation via Ubuntu Studio Installer. This should lead to a much smaller initial download. Unlike creating a version with a different desktop environment, the Ubuntu Technical Board has been on record as saying this would not require going through the new flavor creation process. Our friends at Xubuntu recently did something similar.
Get Involved!
A wonderful way to contribute is to get involved with the project directly! We’re always looking for new volunteers to help with packaging, documentation, tutorials, user support, and MORE! Check out all the ways you can contribute!
Our project leader, Erich Eickmeyer, is now working on Ubuntu Studio at least part-time, and is hoping that the users of Ubuntu Studio can give enough to generate a monthly part-time income. Your donations are appreciated! If other distributions can do it, surely we can! See the sidebar for ways to give!
Special Thanks
Huge special thanks for this release go to:
- Eylul Dogruel: Artwork, Graphics Design
- Ross Gammon: Upstream Debian Developer, Testing, Email Support
- Sebastien Ramacher: Upstream Debian Developer
- Dennis Braun: Upstream Debian Developer
- Rik Mills: Kubuntu Council Member, help with Plasma desktop
- Scarlett Moore: Kubuntu Project Lead, help with Plasma desktop
- Zixing Liu: Simplified Chinese translations in the installer
- Simon Quigley: Lubuntu Release Manager, help with Qt items, Core Developer stuff, keeping Erich sane and focused
- Steve Langasek: Help with livecd-rootfs changes to make the new installer work properly.
- Dan Bungert: Subiquity, seed fixes
- Dennis Loose: Ubuntu Desktop Provision (installer)
- Lukas Klingsbo: Ubuntu Desktop Provision (installer)
- Len Ovens: Testing, insight
- Wim Taymans: Creator of PipeWire
- Mauro Gaspari: Tutorials, Promotion, and Documentation, Testing, keeping Erich sane
- Krytarik Raido: IRC Moderator, Mailing List Moderator
- Erich Eickmeyer: Project Leader, Packaging, Development, Direction, Treasurer
A Note from the Project Leader
When I started out working on Ubuntu Studio six years ago, I had a vision of making it not only the easiest Linux-based operating system for content creation, but the easiest content creation operating system… full-stop.
With the release of Ubuntu Studio 24.04 LTS, I believe we have achieved that goal. No longer do we have to worry about whether an application is JACK or PulseAudio or… whatever. It all just works! Audio applications can be patched to each other!
If an audio device doesn’t depend on complex drivers (i.e. if the device is class-compliant), it will just work. If a user wishes to lower the latency or change the sample rate, we have a utility that does that (Ubuntu Studio Audio Configuration). If a user wants to have finer control use pure JACK via QJackCtl, they can do that too!
I honestly don’t know how I would replicate this on Windows, and replicating on macOS would be much harder without downloading all sorts of applications. With Ubuntu Studio 24.04 LTS, it’s ready to go and you don’t have to worry about it.
Where we are now is a dream come true for me, and something I’ve been hoping to see Ubuntu Studio become. And now, we’re finally here, and I feel like it can only get better.
-Erich Eickmeyer






























 Kubuntu 24.04 with Plasma 5.27.11
Kubuntu 24.04 with Plasma 5.27.11



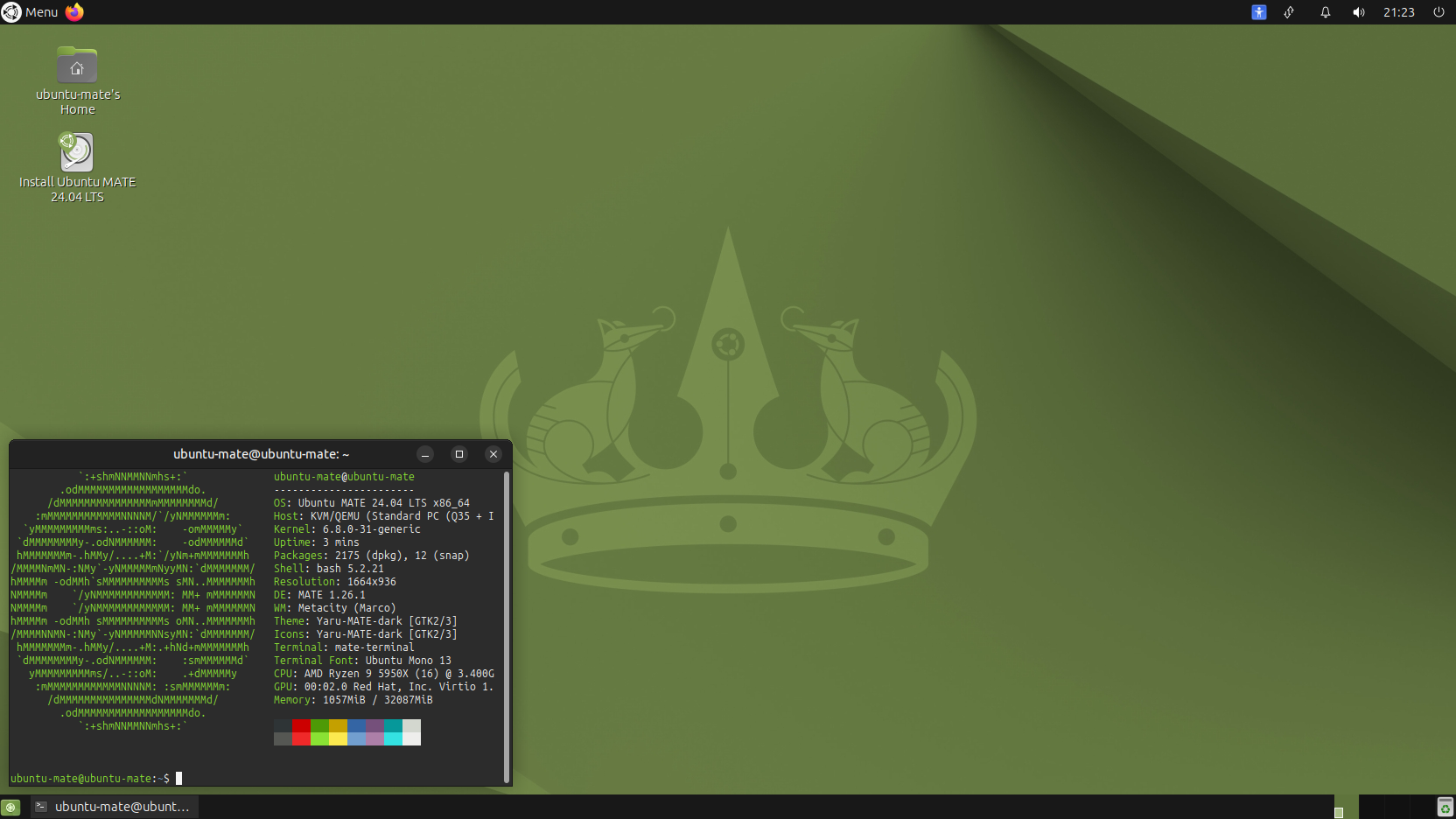 Ubuntu MATE 24.04 LTS
Ubuntu MATE 24.04 LTS


 Xubuntu 24.04, featuring the latest updates from Xfce 4.18 and GNOME 46.
Xubuntu 24.04, featuring the latest updates from Xfce 4.18 and GNOME 46.
 Ubuntu MATE 23.10
Ubuntu MATE 23.10